Per una linea di produzione i parametri rilevanti da monitorare sono l’output, il tempo totale di produzione e la frequenza di arresto della linea. Prtg Network Monitor di Paessler, pur essendo tradizionalmente considerato una soluzione per il monitoraggio di rete, può fare anche altro. Unendo varie tecniche e idee, è stato possibile implementare un monitoraggio in presa diretta di una linea di produzione, in grado di offrire dati preziosi per decisioni di business e tecniche, nonché per migliorare l’output.
La sfida
La linea di produzione in questione realizza attrezzature mediche monouso. La linea è gestita da un sistema di controllo centrale proprietario open loop, già collegato a vari sensori lungo la linea di produzione. Per quanto sia tecnicamente possibile ricavare informazioni sull’output dal sistema di controllo stesso, ciò è realizzabile solamente mediante un’interfaccia software proprietaria molto costosa. Di conseguenza non avevamo a disposizione alcun dato su quanti prodotti venivano realizzati, in che tempi, quando avvenivano bug nella produzione e altri importanti dettagli. Finora i dati di produzione disponibili venivano raccolti manualmente su moduli cartacei o inseriti in un questionario digitale post produzione. La linea di produzione o il sistema di controllo non potevano essere alterati o interfacciati direttamente, a causa degli standard di validazione e verifica estremamente complessi allora necessari (ISO 13485/FDA ambienti normati).
L’idea
L’idea era installare sensori passivi che riconoscessero gli oggetti che scorrono sulla linea, raccogliere i dati in un hub centrale per il successivo trattamento e fornire una comoda interfaccia utente grafica per le metriche di produzione.
La soluzione
Trattandosi di un’unità produttiva, la scelta più ovvia era Raspberry PI, sia per la semplicità di installazione dei sensori sia per la grande quantità di tutorial disponibili. Dapprima sono stati testati e usati i sensori di distanza a ultrasuoni per monitorare direttamente il passaggio degli oggetti, scoprendo che avvenivano troppe false letture poiché gli operatori di linea interferivano con i sensori. Così è stata trovata una soluzione migliore: la combinazione di sensori magnetici e pneumatici che monitorano il movimento delle stazioni lungo la linea (ad esempio bracci robotizzati che spostano o saldano gli oggetti).
Sul fronte software, i due esperti hanno deciso di usare script scritti in Python che processano le informazioni e le caricano su Prtg Network Monitor. Questo ha permesso di raccogliere i dati e di visualizzare in tempo reale grafici e tabelle di facile lettura che vengono costantemente aggiornate nel corso della giornata. La funzione mappe di Prtg è stata utilizzata per pubblicare un URL per monitorare il progresso attuale della produzione e intercettare i bug di produzione.
I dati raccolti e pre-processati sono ulteriormente scritti in log distinti per ciascun sensore. Due volte al giorno i log vengono letti da uno script cronjob che riassume in un report inviato per email le metriche di produzione significative.
Come funziona
Come già detto, l’obiettivo è monitorare le stazioni lungo la linea: se una stazione si muove – ad esempio un braccio robotizzato che cambia posizione – assumiamo che stia lavorando su qualcosa e quindi aumentiamo di uno la conta totale (un altro elemento si è spostato lungo la linea di produzione). Per monitorare il fenomeno vengono usate tre variabili:
- Ha un valore ‘alto’ o ‘basso’, in funzione dell’indice di inattività configurato nella stazione. Se, ad esempio, un braccio robotizzato è inattivo quando il circuito è aperto, dovrà avere il valore ‘basso’. Quando il circuito è chiuso, avrà un valore ‘alto’. Possiamo così assumere, in questo particolare esempio, che il braccio robotizzato è attivo quando il circuito è chiuso e il valore del segnale è ‘alto’:
- Un numero intero che conta il numero di elementi che si spostano lungo la linea.
- Lo stato della stazione monitorata. Vi sono tre possibilità: ‘inattivo’, ‘attivato’, ‘era attivato’.
Ecco quindi come è stata implementata la soluzione.
I sensori al Raspberry PI sono stati connessi con doppini schermati. Il PI interroga costantemente i sensori in cicli di 100 millisecondi e incrementa la conta di ‘alto’ e ‘basso’ (da zero a un certo valore massimo per prevenire l’overflow). Gli interrupt basati su eventi non sono utilizzabili a causa dell’alto livello di rumore elettromagnetico nell’area. Un segnale ‘alto’ viene sottratto dal totale di ‘low’ e viceversa. In questo modo entrambi gli stati sostanzialmente competono l’uno contro l’altro, sopprimendo il rumore dei sensori. Le false letture sono ulteriormente prevenute applicando un isteresi al riconoscimento.
In pratica avviene che:
- Un sensore parte in uno stato inattivo (‘alto’ o ‘basso’ a seconda dell’installazione del sensore)
- quando un ‘sensor switch’ è attivato, il relativo contatore (il valore ‘alto’ nel precedente esempio del braccio robotizzato) viene incrementato in un array fino a quando viene raggiunta una soglia predefinita. Lo stato della stazione passa quindi da ‘inattivo’ ad ‘attivo’.
- Quando la stazione ritorna a uno stato ‘inattivo’ (ovvero il braccio robotizzato torna a un valore ‘basso’), il totale inizia a diminuire. Quando il totale scende sotto una seconda soglia calcolata dal massimo dell’array, lo stato passa a ‘era attivo’ e quindi nuovamente a ‘inattivo’. Nello stato ‘era attivo’ vengono aggiornati parametri quali la conta degli oggetti, il tempo di rilevamento, ecc.
Aggiornamento su Prtg
Ogni dieci secondi lo script sempre in funzione genera un thread separato che invia in modo indipendente la conta degli oggetti, il tempo di rilevamento, gli intervalli, la temperatura e l’umidità, al relativo sensore push Http di Prtg. Era importante spingere l’upload a un thread separato perché altrimenti la routine di rilevamento si sarebbe bloccata fino al termine dell’upload, che può richiedere alcuni secondi. Si è deciso quindi di definire un sensore push per ogni sensore switch, poiché ogni sensore è interrogato da uno script separato.
È stato perciò regolato a 10 secondi il tempo di intervallo nella configurazione del sistema Prtg (nonché su alcuni altri valori) per ottenere una vista più dettagliata su Live Graph.
Il passo successivo è stato sintetizzare i dati importanti e visualizzarli in una mappa in Prtg. Per riassumere i dati provenienti dai diversi sensori e dai loro canali e visualizzarli in un’unica tabella è stato usato il sensore Sensor Factory, combinando alcuni grafici per mostrarne l’andamento.
Il progetto ha inoltre voluto dimostrare come procedesse la produzione in ogni specifico momento in rapporto al tempo di produzione trascorso. Ciò è stato realizzato scrivendo uno script che invia continuamente l’ora attuale, in minuti, a un diverso sensore. Questo ha permesso di calcolare la percentuale di tempo trascorso durante la giornata di produzione corrente rispetto ai prodotti realizzati in termini percentuali rispetto all’obiettivo globale del giorno. Usando questi due valori è possibile verificare se siamo o meno in linea con gli obiettivi.
Questo calcolo è stato essenziale per poter reagire in tempo reale ai ritardi negli output di produzione. La frequenza di produzione, ovvero gli output in scansione oraria, permette di ottenere un’analisi storica per misurare i miglioramenti.
I risultati
Questo è quanto è possibile vedere sull’immagine della mappa:
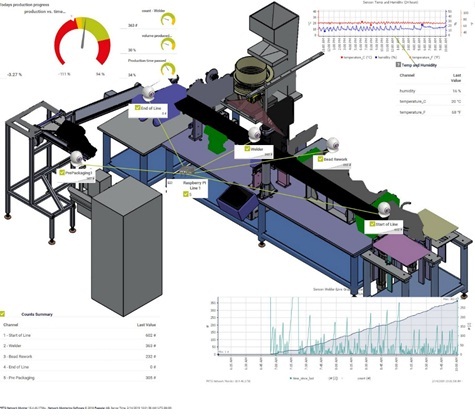{kind=link}
La linea va da destra a sinistra ed è possibile vedere i sensori installati lungo la linea. La maggior parte dei sensori determina solamente quanti prodotti sono passati per un dato punto della linea di produzione. C’è un sensore, denominato Bead Rework, che conta le parti rifiutate che devono essere ripassate dopo l’intervento degli operatori di linea.
Nell’angolo superiore sinistro dell’immagine si vede il tempo di produzione rispetto al calcolo del totale prodotto. Se l’indicatore si trova nell’area rossa, la produzione è in ritardo rispetto ai piani. Sul lato destro si vede un semplice grafico che indica umidità e temperatura (fattori importanti per l’oggetto prodotto).
Nell’angolo inferiore sinistro si trova una tabella riassuntiva basata sul sensore Sensor Factory che indica quante parti sono passate per ciascun punto della linea.
Nell’angolo inferiore destro si trova un grafico delle performance. Questo grafico è importante per comprendere come si sta comportando la linea di produzione. La linea bianca indica il numero di prodotti che sono passati per un determinato sensore. La linea verde indica la differenza tra due conteggi, ovvero la durata del ciclo. Idealmente la linea dovrebbe rappresentare un plateau rettilineo a un livello molto basso. Se la linea si interrompe o nessun prodotto viene processato, il tempo ‘morto’ tra le parti aumenta. Tempi morti alti significano che si è verificato un problema, forse dovuto a un alto tasso di rifiuto delle parti o perché la produzione è stata interrotta per qualche motivo.
Altre mappe che contengono grafici più dettagliati sono state create. Alcuni utenti selezionati possono inoltre accedere a Prtg e visualizzare le serie storiche.
Una volta disponibili le metriche iniziali di produzione, abbiamo voluto indagare le ragioni delle interruzioni della produzione. Per raccogliere questi dati abbiamo fornito agli operatori una semplice app con interfaccia touch da utilizzare per registrare guasti ed errori in tempo reale. Nelle mappe è incluso anche un riepilogo live degli errori giornalieri.
Esempi di codice
Per capire come siamo arrivati a questi risultati abbiamo reso disponibili alcuni campioni di codice e di script in un file Zip. Abbiamo incluso il codice Raspberry PI e lo script PowerShell.
Ulteriori informazioni sono disponibili sul sito di Florian: https://www.it-admins.com/